Computationally Efficient#
Whether you’re working with in-memory or out-of-memory data, xeofs ensures computational efficiency. This is achieved using randomized SVD, which is typically faster for large matrices than a full SVD. For more details, refer to the sklearn documentation on PCA.
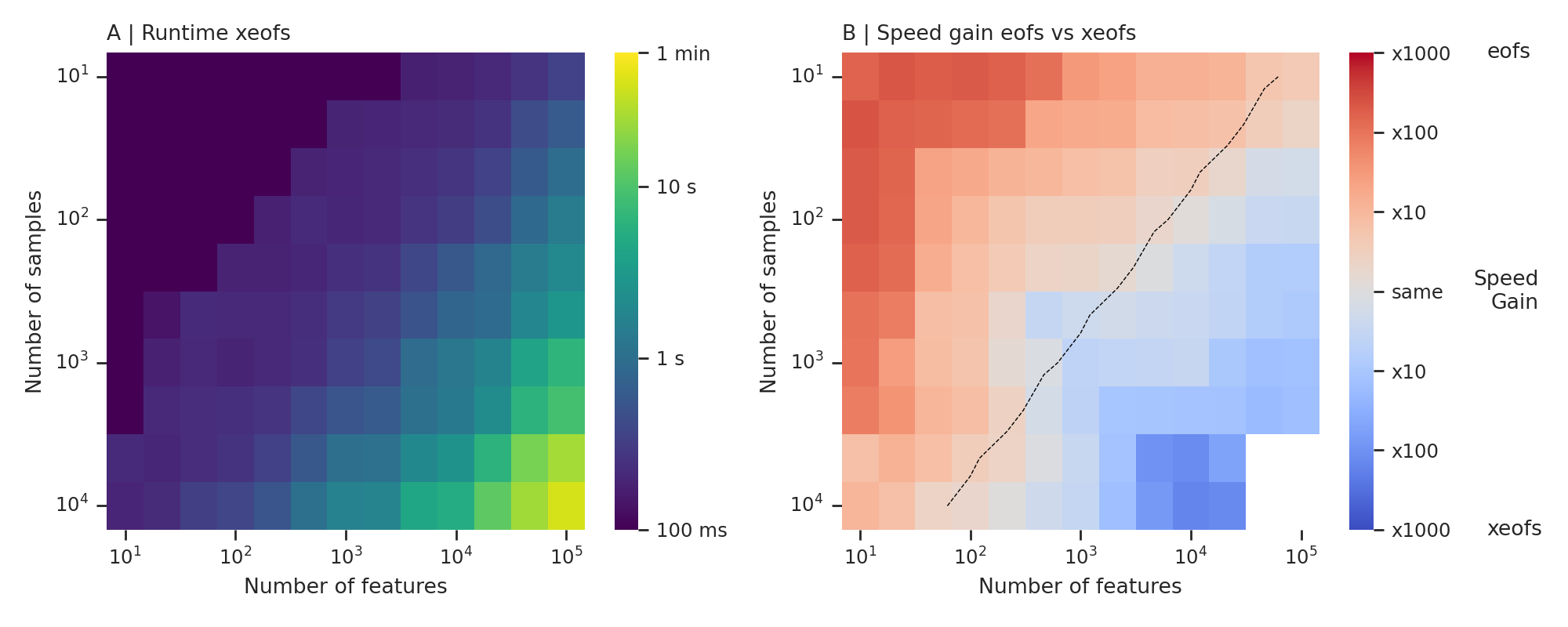
A comparative analysis demonstrates the performance of xeofs against eofs on a standard laptop using a 3D dataset with time, longitude, and latitude dimensions. Results indicate that xeofs computes moderate datasets (10,000 samples by 100,000 features) in under a minute. While eofs is faster for smaller datasets, xeofs excels with larger datasets, offering significant speed advantages. The dashed line marks datasets with about 3 MiB; xeofs outpaces eofs above this size, whereas eofs is preferable for smaller datasets.
Comparison of computational times between xeofs and eofs for data sets of varying sizes

Note
You can find the script to run the performance tests here.